Introduction
This guide describes how to create Argo components using Maven archetypes, and how to package these components for installation into the Argo platform.
Argo components are simply Apache UIMA components, however certain rules (specified within this document) must be adhered to for them to be fully-compliant with the Argo platform.
The projects produced by the Maven archetypes make use of the Apache uimaFIT library which, amongst other things, allows component metadata to be included with a component’s source code and then extracted into an automatically generated UIMA XML metadata descriptor file.
Creating a new project
Creating a new project using Eclipse
-
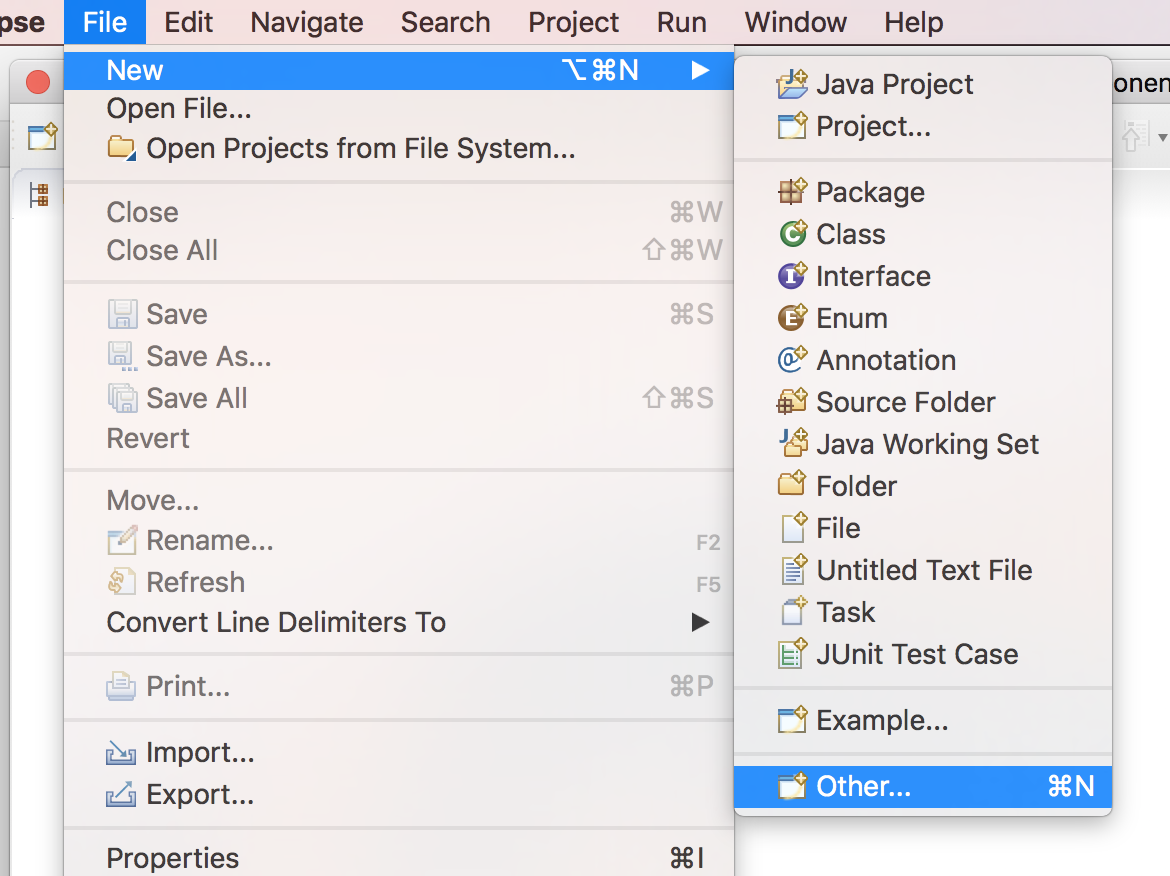
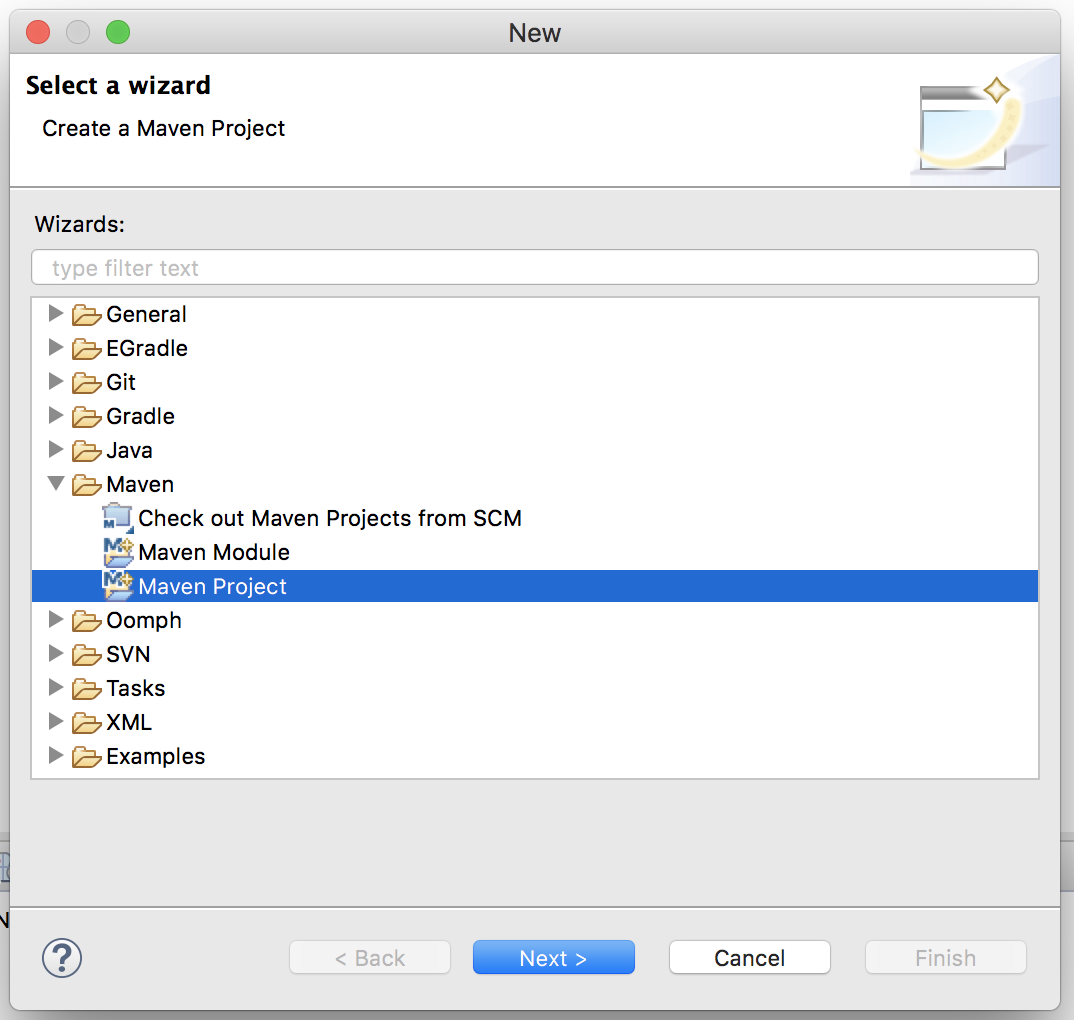
From the top menu navigate to File → New → Other… and a new dialog window will appear.
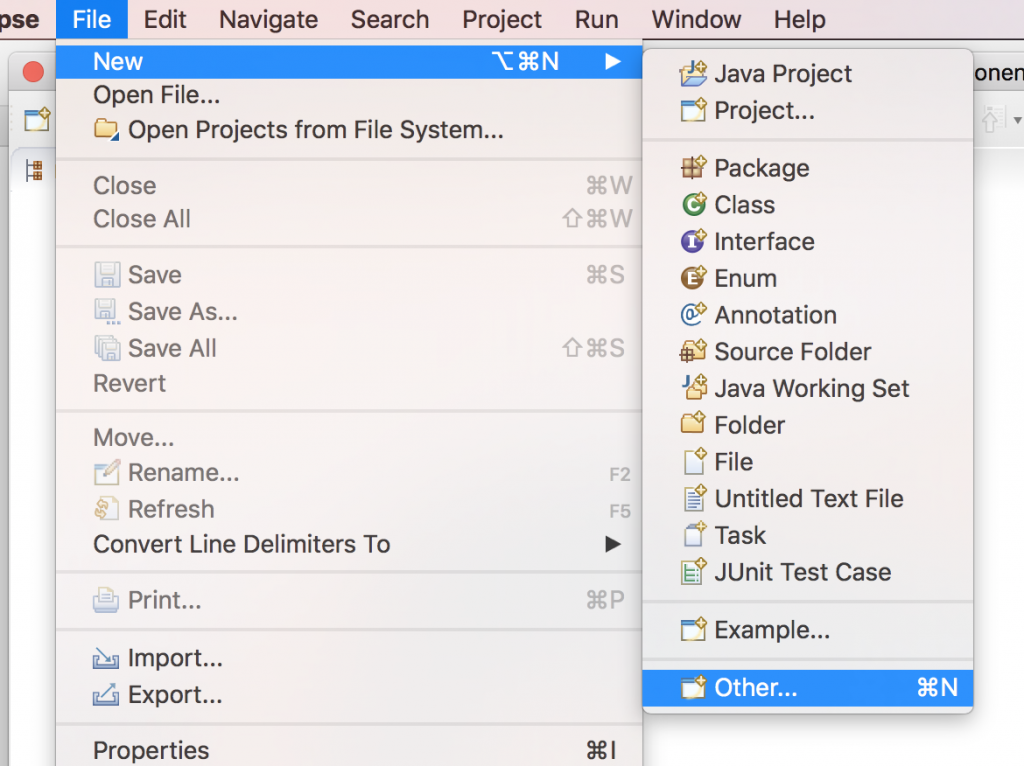
- Open up the Maven item in the list, select Maven Project and then press Next.
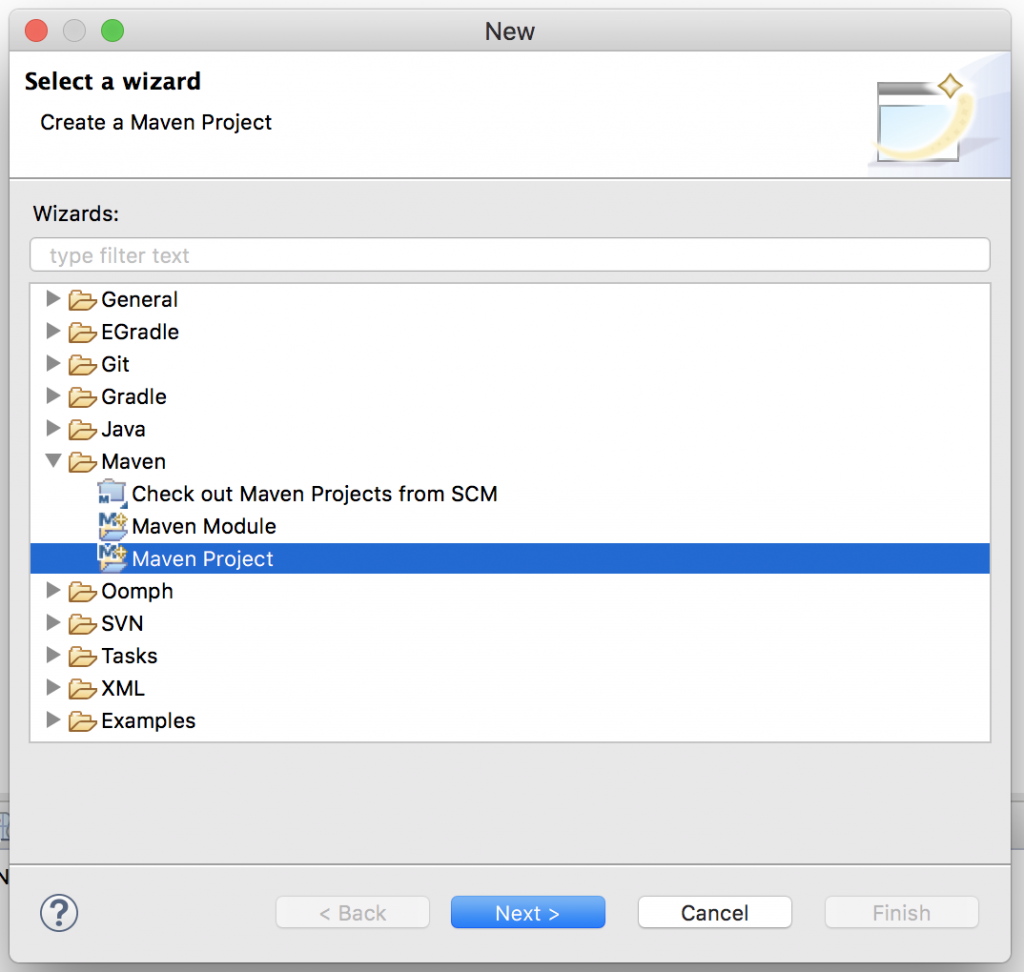
-
On the next page, simply press Next.

-
From the list of archetypes, select either argo-reader-archetype (for creating an Argo Reader) or argo-analysis-engine-archetype (for creating an Argo Analysis Engine). If these archetypes do not appear in the list, then they first must be added (see below).
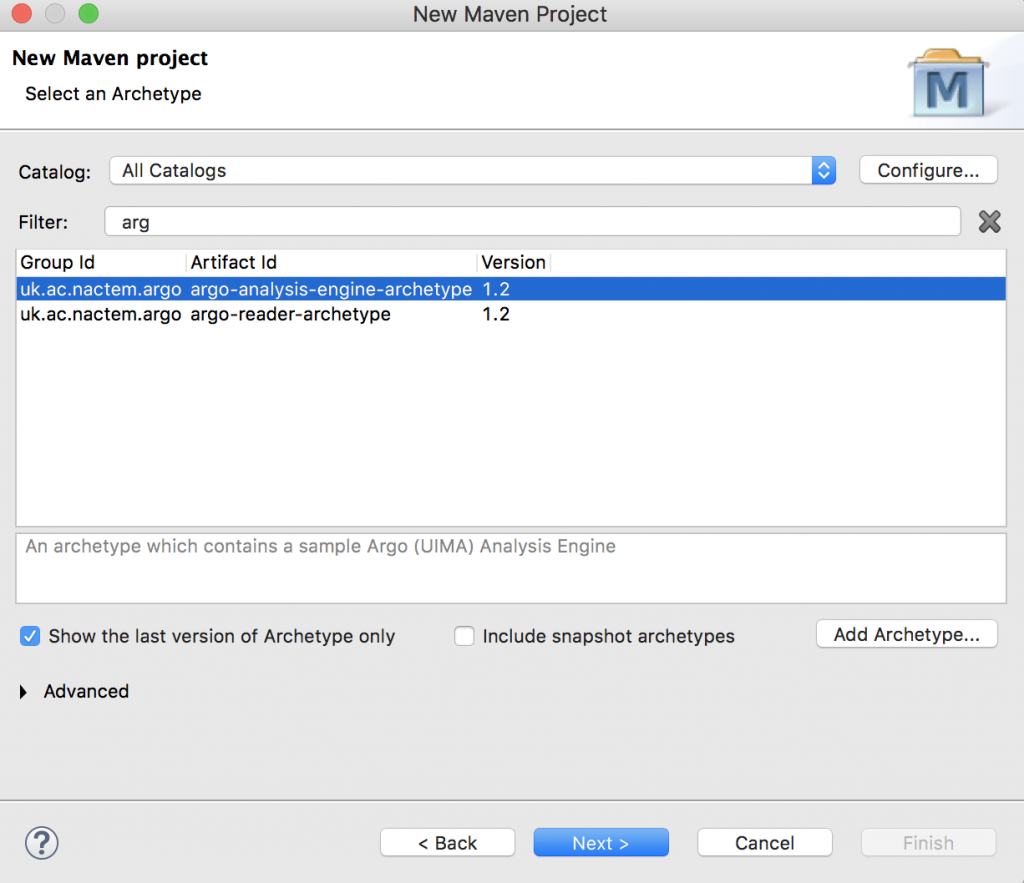
To add the Maven archetypes to Eclipse:
-
Press the Add Archetype.. Button.
-
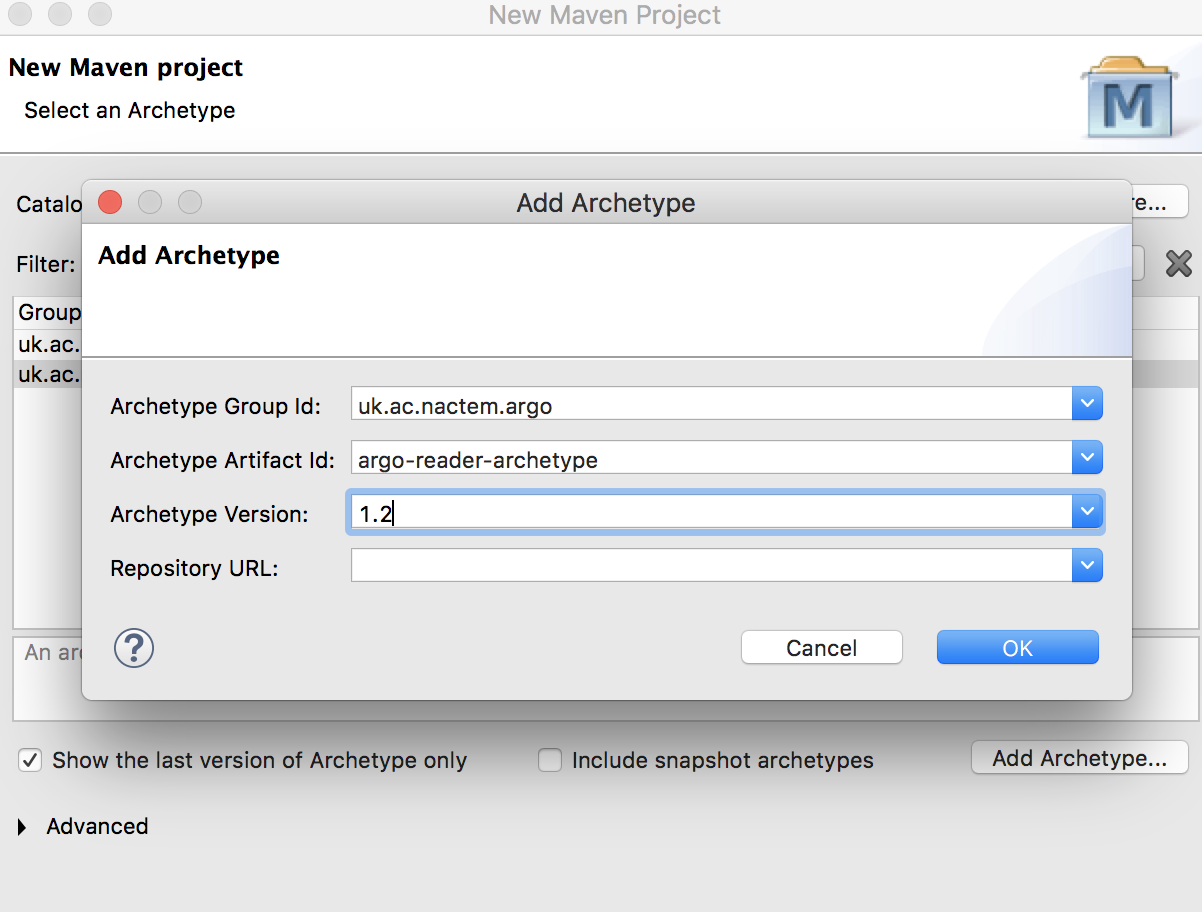
To add the Argo Reader archetype enter the following values and press OK:
-

|
Archetype Group Id |
uk.ac.nactem.argo |
|
Archetype Artifact Id |
argo-reader-archetype |
|
Archetype Version |
1.2 |
-
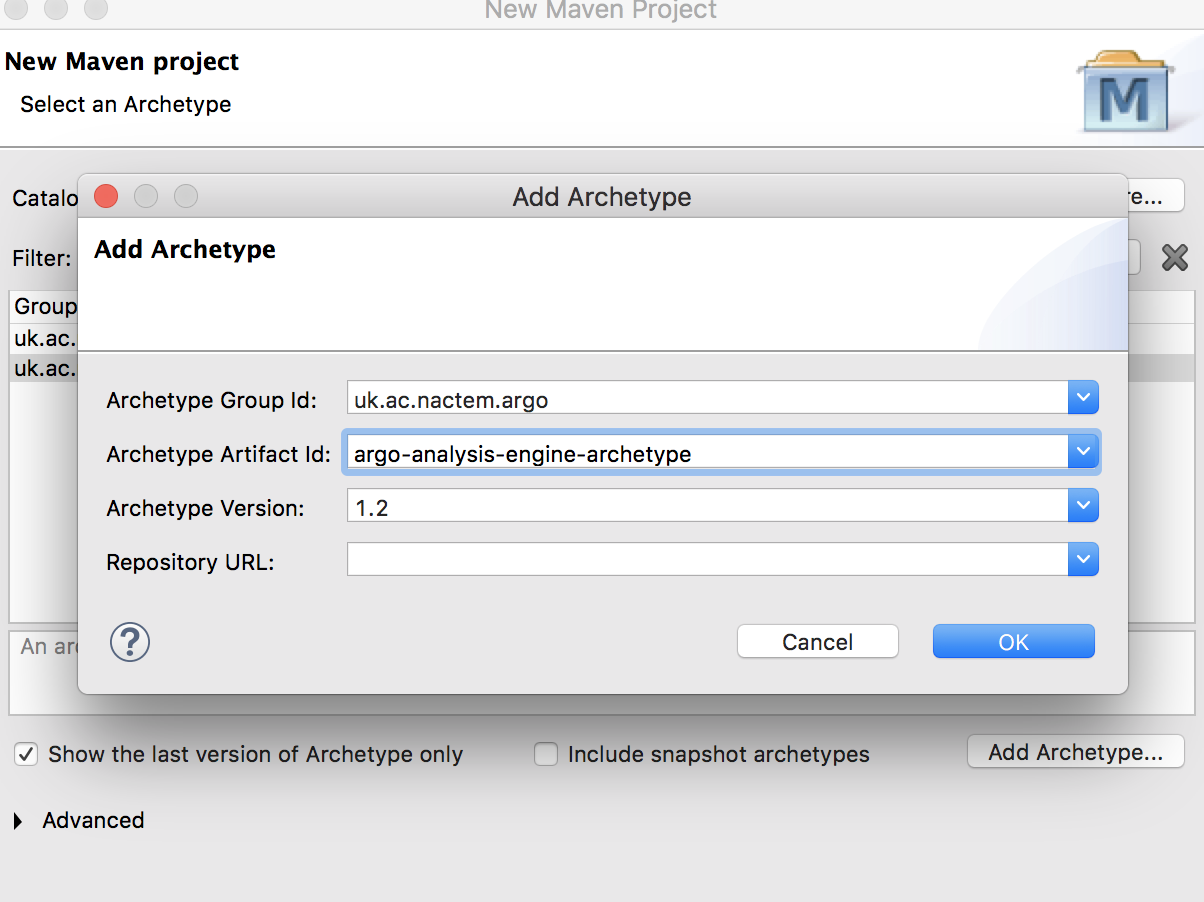
To add the Argo Analysis Engine archetype enter the following values and press OK:
|
Archetype Group Id |
uk.ac.nactem.argo |
|
Archetype Artifact Id |
argo-analysis-engine-archetype |
|
Archetype Version |
1.2 |
-
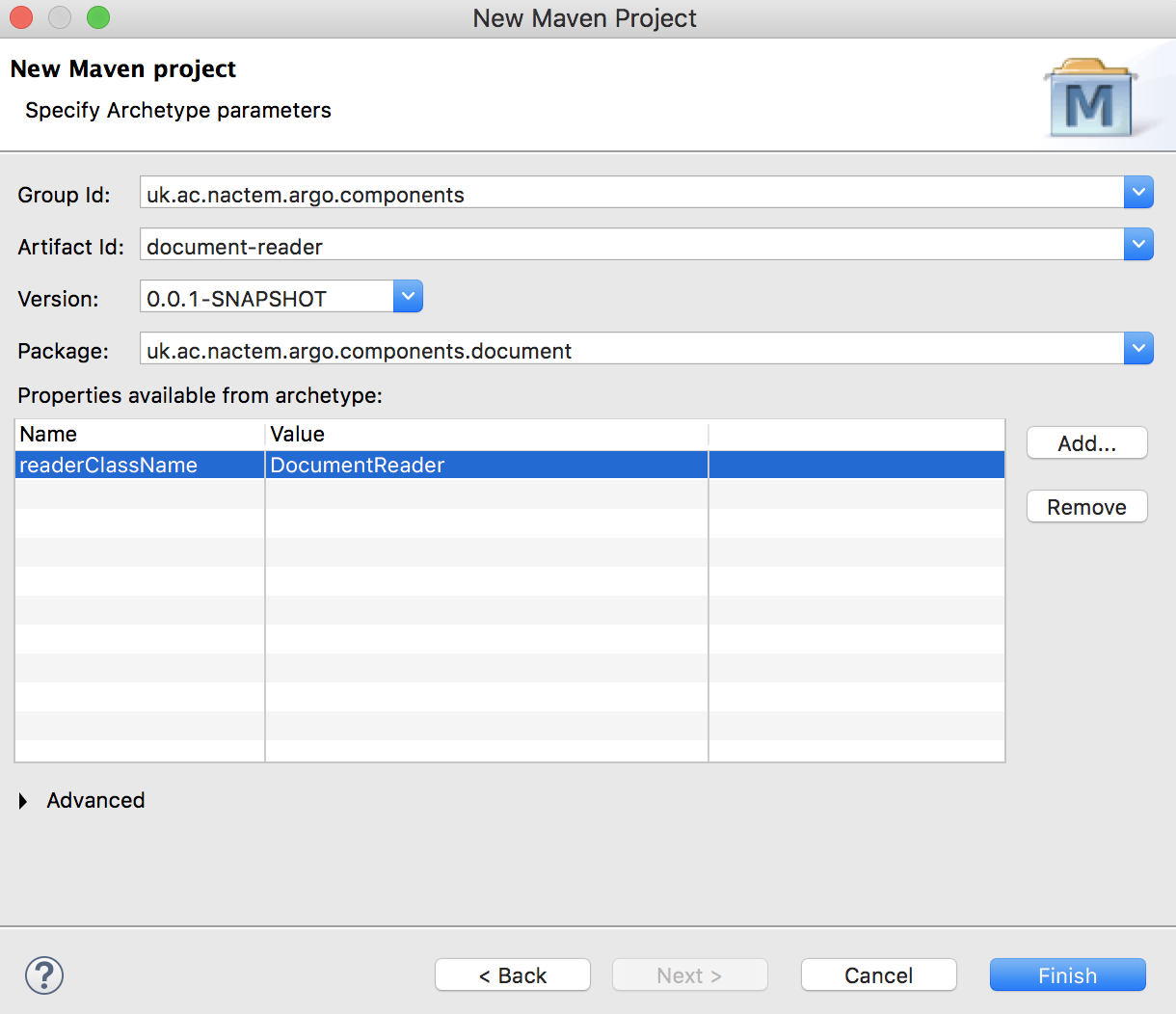
Once the Maven archetype has been selected, a number of property values are required before the sample project can be generated.
Both of the Argo archetypes require 4 basic properties:
|
Group Id |
The Maven group id of the new component |
|
Artifact Id |
The Maven artifact id of the new component (e.g. magic-analysis-engine, document-reader) |
|
Version |
The Maven version of the new component (e.g. 0.0.1-SNAPSHOT, 1.0) |
|
Package |
The Java package to contain the new component’s main class (e.g. uk.ac.nactem.argo.components.magic) |
The Argo Reader archetype also requires the property:
|
readerClassName |
The name of the new reader’s main Java class |
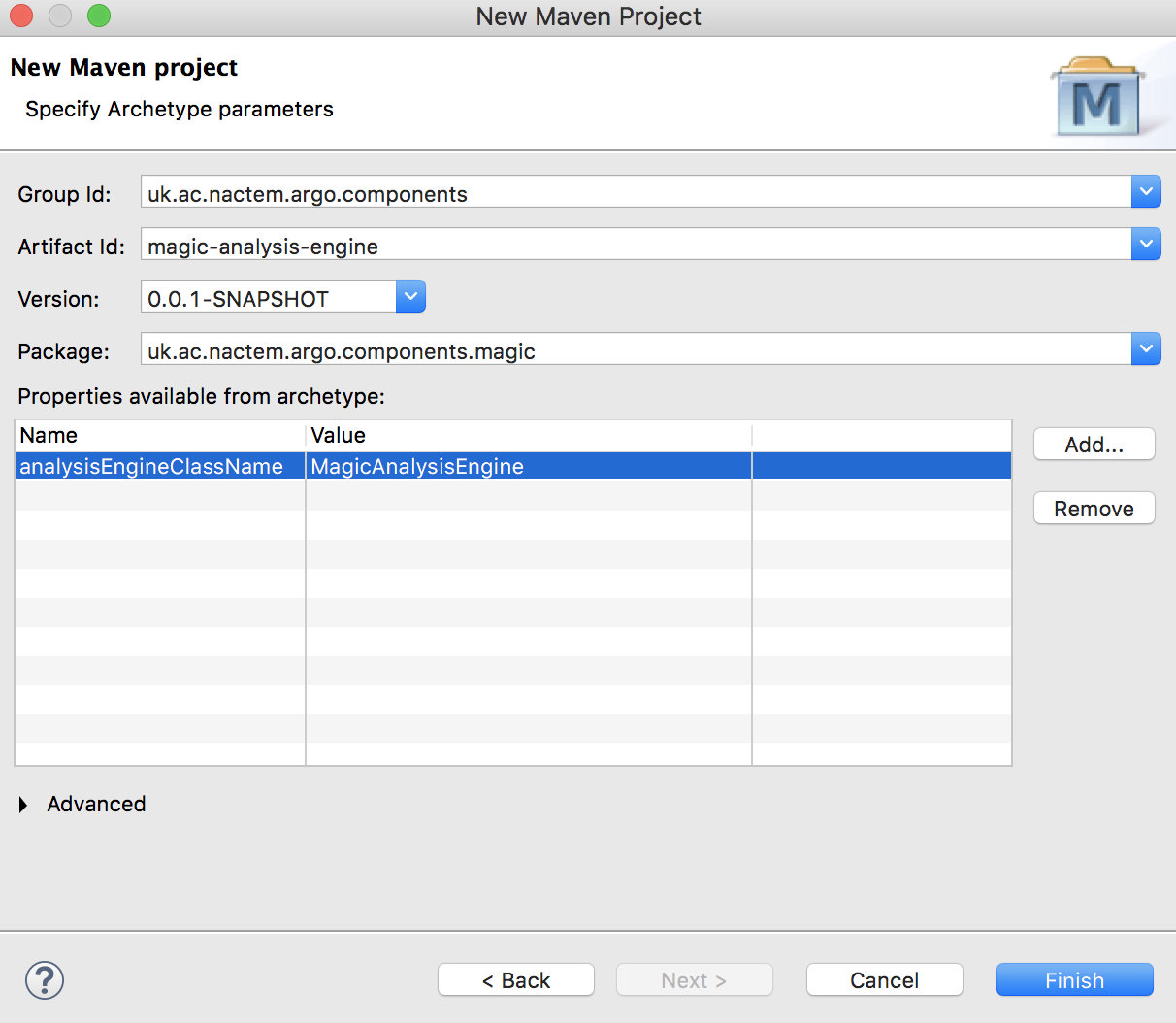
The Argo Analysis archetype requires the property:
|
analysisEngineClassName |
The name of the new analysis engine’s main Java class |
-
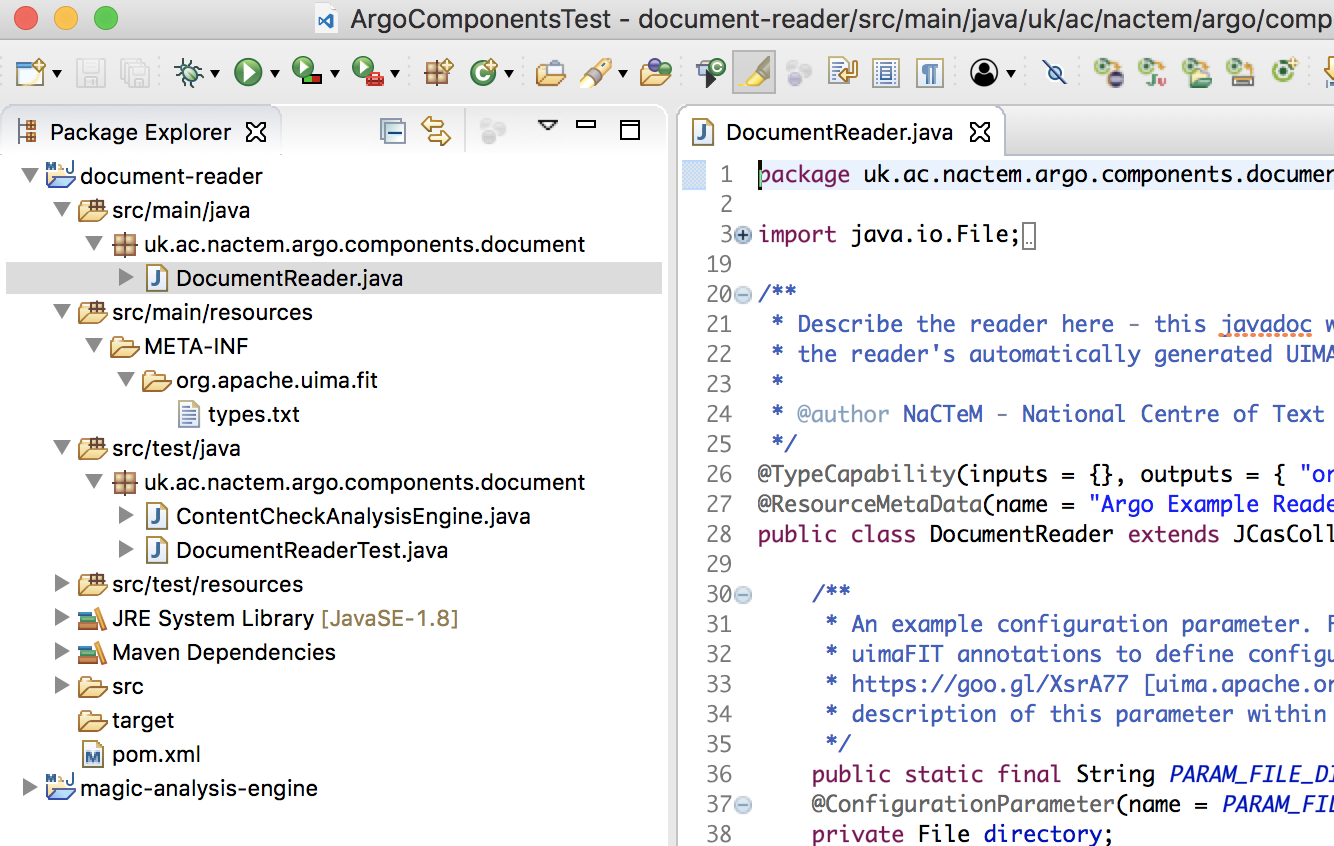
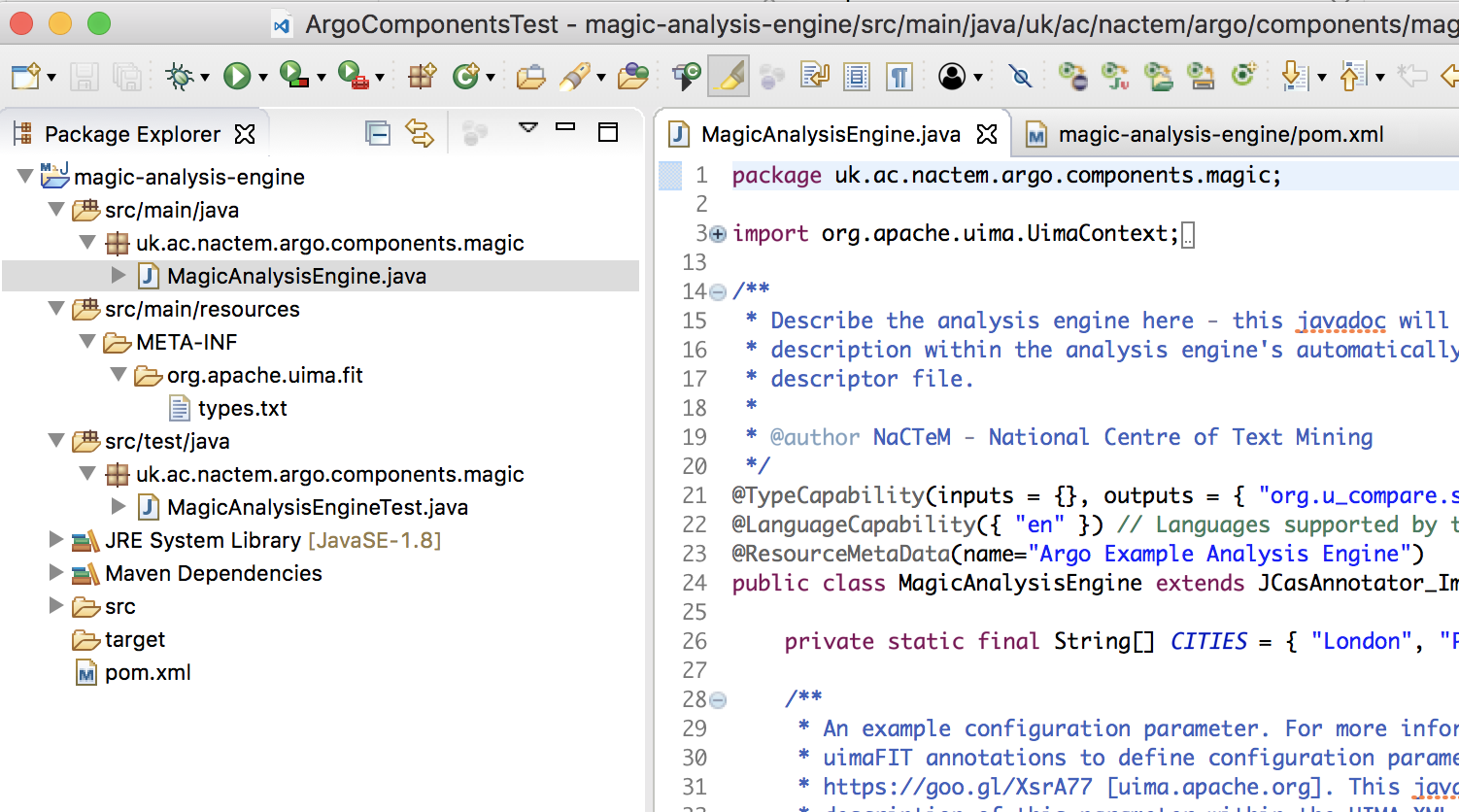
Press the Finish button and the new project, containing either a sample Argo reader or analysis engine, will be visible within the Eclipse workspace.
Creating a new project from the command line
Apache Maven must be installed before projects can be created from the command line. Please see the previous section ‘Creating a new project in Eclipse’ for an explanation of the archetype parameters (e.g. readerClassName) in the following commands.
-
To create a new project containing a sample Argo reader:
|
mvn archetype:generate \ -DarchetypeGroupId=uk.ac.nactem.argo \ -DarchetypeArtifactId=argo-reader-archetype \ -DarchetypeVersion=1.2 \ -DgroupId=<Group Id> \ -DartifactId=<Artifact Id> \ -Dversion=<Version> \ -Dpackage=<Package> \ -DreaderClassName=<Reader Class Name> |
-
To create a new project containing a sample Argo analysis engine:
|
mvn archetype:generate \ -DarchetypeGroupId=uk.ac.nactem.argo \ -DarchetypeArtifactId=argo-analysis-engine-archetype \ -DarchetypeVersion=1.2 \ -DgroupId=<Group Id> \ -DartifactId=<Artifact Id> \ -Dversion=<Version> \ -Dpackage=<Package> \ -DanalysisEngineClassName=<Analysis Engine Class Name> |
Using Type Systems within a component
When using a type system within either an Argo reader or analysis engine:
-
Add the type systems’s maven artifact to the main dependencies list within the component’s POM file.
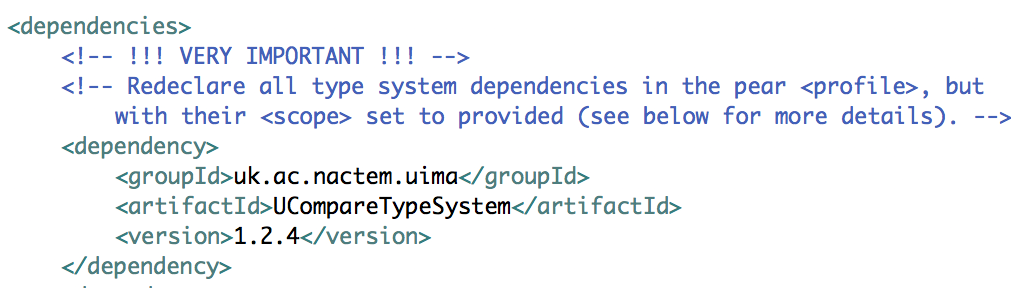
-
Add the type systems’s maven artifact to the dependencies list within the pear profile in the component’s POM file, but this time setting it’s scope to provided. This is to prevent the type system being included in the component’s PEAR file; the type system will be independently installed into Argo from its own PEAR file. If a type system is also included inside a component’s PEAR file then workflows containing this component will most likely fail during execution.
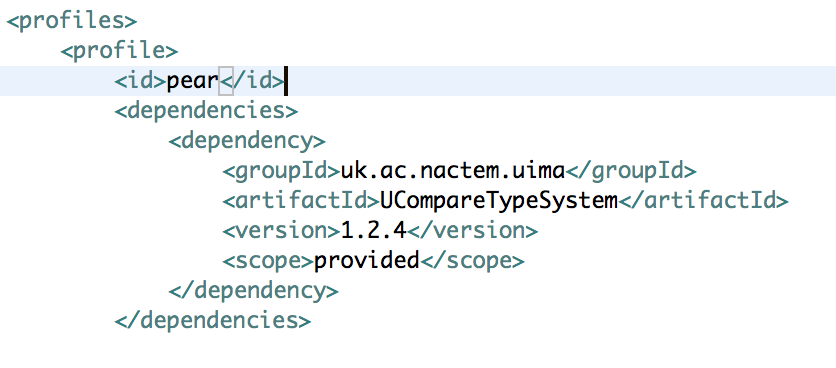
-
It maybe necessary to add the path to the type system’s descriptor into the component’s META-INF/org.apache.uima.fit/types.txt file. This is only required if the type system artifact doesn’t already include this file (The version of the U-Compare type system on GitHub does include it however, for demonstration purposes, the type system is redeclared within the components generated from the Maven archetype). The types.txt file is used by the uimaFIT mechanism for automatically detecting type systems.
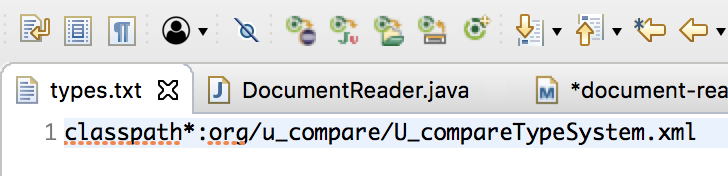
Building PEAR files for Argo installation
Argo components (and type systems) are installed by Argo administrators from PEAR files.
To produce an Argo-compatible PEAR file, from a project generated using the provided Maven archetypes, requires running the Maven goal install using the supplied pear profile.
Building a PEAR file in Eclipse
An Eclipse launch configuration needs to be created, which will use maven to produce the PEAR file. Creating the launch configuration only needs to be done once per project in an Eclipse workspace.
-
Right-click on the project in Package Explorer and navigate to Run As → Maven build…
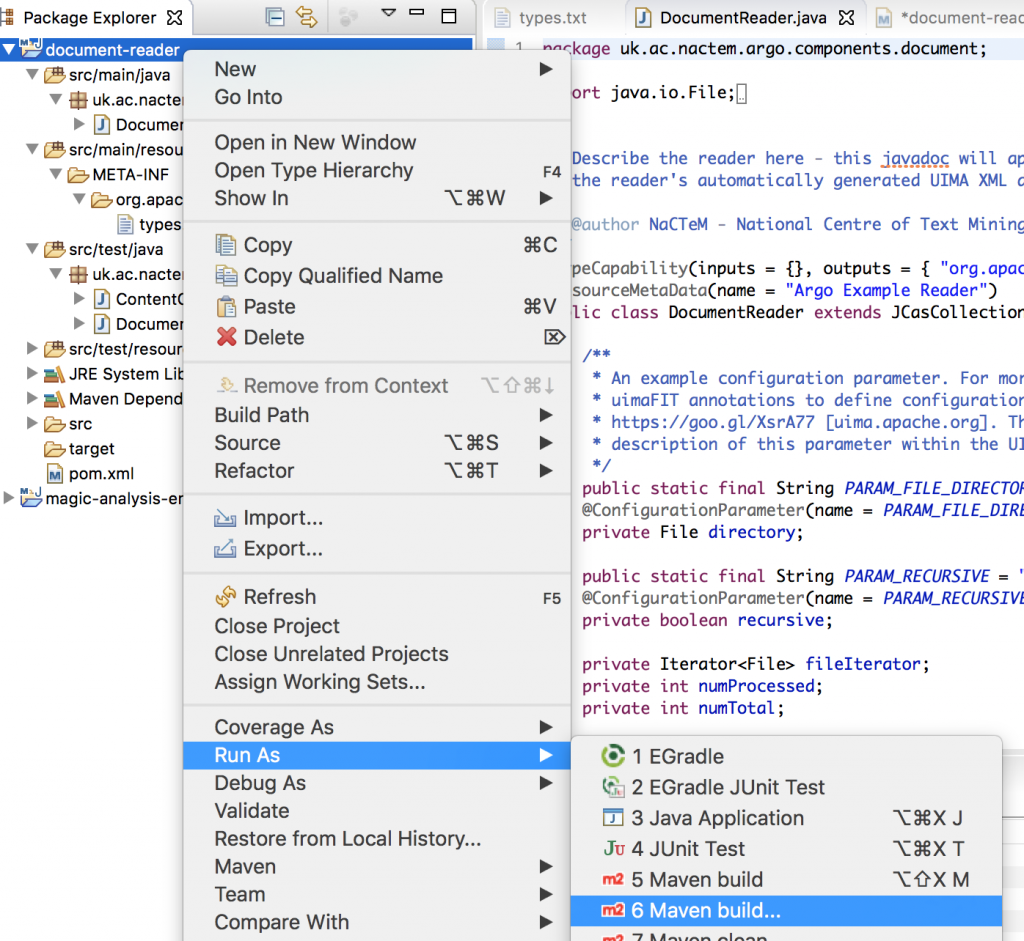
-
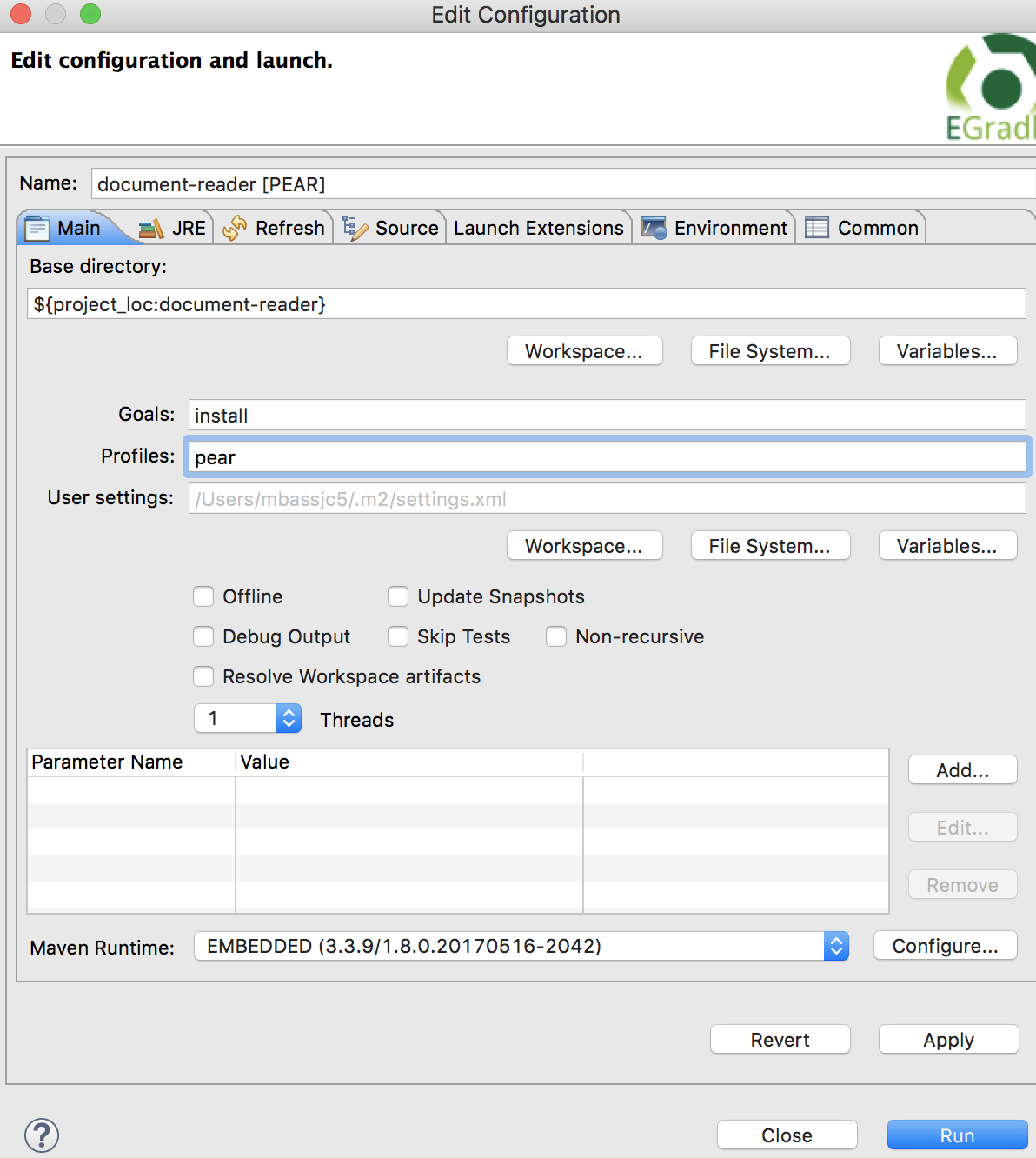
A dialog window will appear, entitled ‘Edit Configuration’. In this window change the settings:

|
Name |
A distinguishable identifier (e.g. document-reader [PEAR]) |
|
Goals |
install |
|
Profiles |
pear |
Building a PEAR file from the command line
-
Navigate to the project folder – this will contain the Maven POM file.
|
cd /path/to/project |
-
Use Maven to produce the PEAR file.
|
mvn install -P pear |
Using components within uimaFIT pipelines
Argo components created from the provided Maven archetypes and developed using the guidelines in this document should be fully compatible with uimaFIT pipelines, without any changes being required.
Renaming or moving the main component class
It is acceptable to rename or move the main class of a component to another Java package, after a project has been generated from one of the Maven archetypes, however a change is required in the Maven POM file.
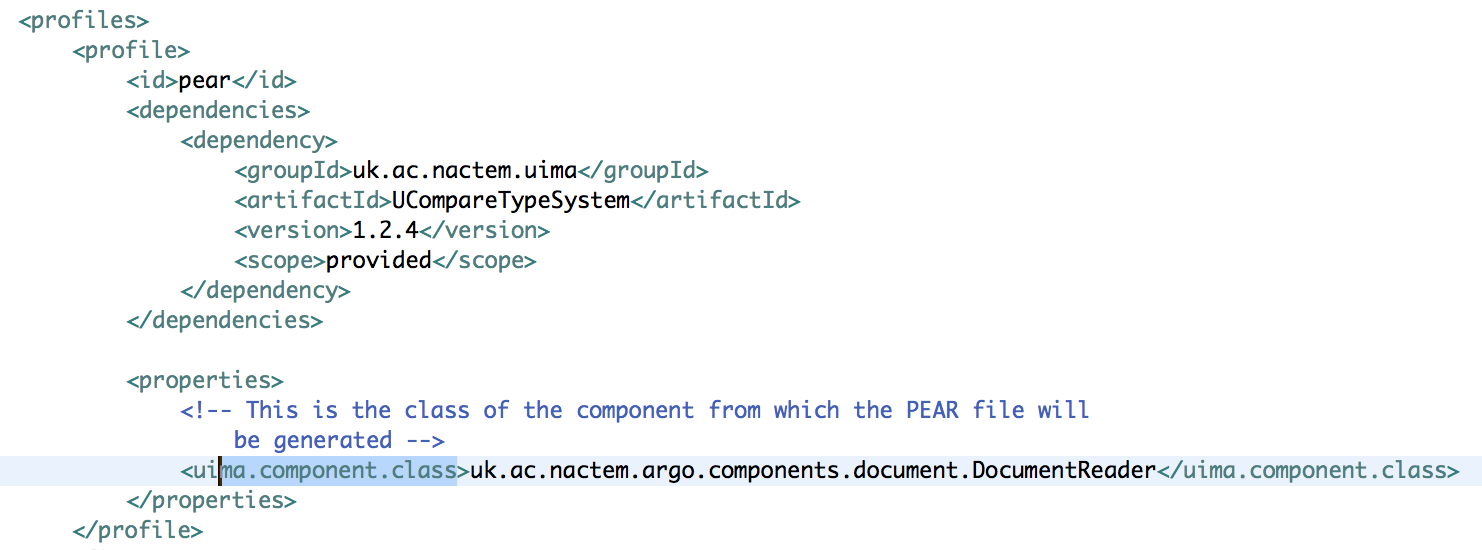
The new fully qualified name (e.g. uk.ac.nactem.argo.components.ChangedName) of the main component Java class must be given as the value of the uima.component.class property inside of the pear profile within the Maven POM file.
Accessing the Argo file system from a component
At present, only components which are running on the same machine as the Argo server installation have access to files stores within Argo.
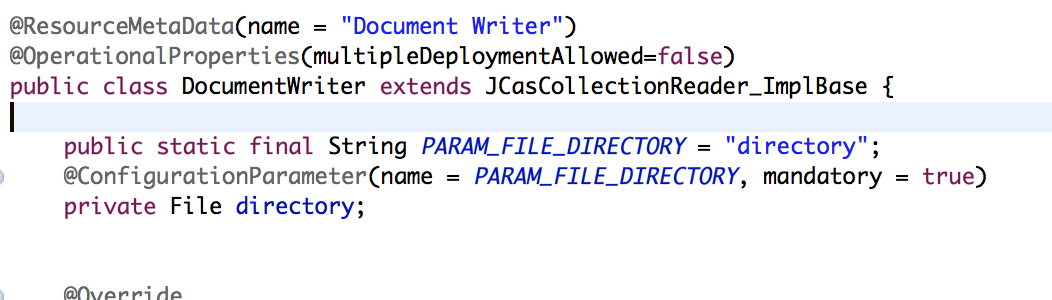
For distributed workflows, Argo will automatically run reader components on the Argo server (giving them access to the file system), but if a regular analysis engine requires file access, it must have its uima property of multipleDeploymentAllowed set to false. This will ensure that the component is not distributed, and is executed upon the Argo server.
So, to allow an analysis engine access to the Argo file system, the uimaFIT @OperationalProperties annotation must be added to the component’s class with its multipleDeploymentAllowed attribute set to false.
Note about Argo consumers
Argo traditionally supports 3 types of components (readers, analysis engines and consumers) which are essentially the 3 types of components initially supported by the Apache UIMA framework.
Apache UIMA recommends that consumers no longer be developed; an analysis engine can perform exactly the same role. Apache uimaFIT, a UIMA-based library used by the Maven archetypes for Argo, doesn’t support consumers at all – for example, they cannot be used within a uimaFit workflow.
The recommendation, when developing Argo components, is to follow the approach of UIMA and uimaFIT and consider consumers to be deprecated – this is why there is no Maven archetype to create consumer components.